环境:A800 NVLink连接,
结果:cudaMemcpy 187GB/s SM load/store 29GB/s
__global__ void smMemcpyKernel64(const void* _dst, const void* _src, size_t size, int nThreads) {
//threadIdx.x =
//blockIdx.x =
uint64_t count = (size+7)/8;
uint64_t *src = (uint64_t*)_src;
uint64_t *dst = (uint64_t*)_dst;
int tid = blockIdx.x*blockDim.x + threadIdx.x;
uint64_t loop = count/nThreads;
uint64_t left = count%nThreads;
if(size <= nThreads) {
if(tid <= count) {
dst[tid] = src[tid];
}
} else {
#pragma unroll
for(int i=0; i<loop; i++) {
dst[tid*loop+i] = src[tid*loop+i];
}
if(tid == nThreads-1) {
#pragma unroll
for(int i=0; i<left; i++) {
dst[(tid+1)*loop+i] = src[(tid+1)*loop+i];
}
}
}
}

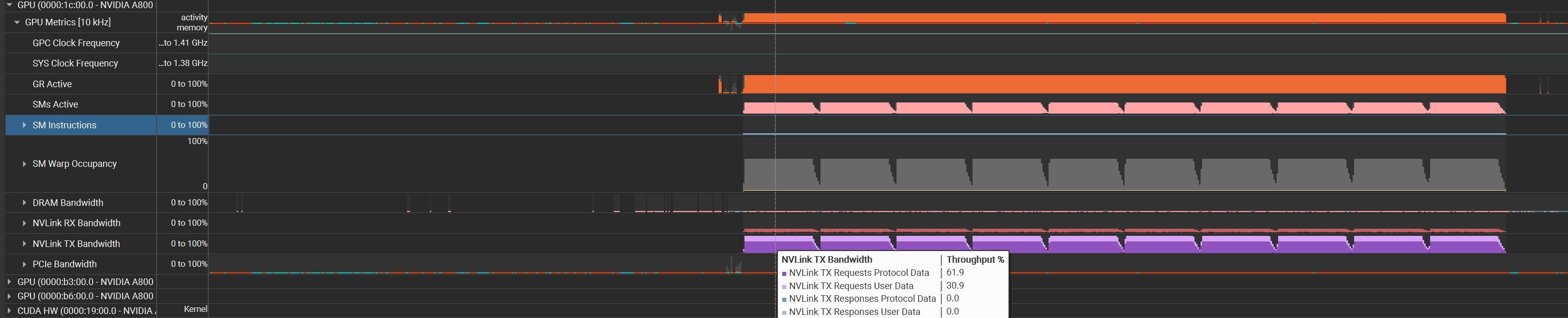
nsys显示SM load/store时,GR active 接近100%,nvlink只有61%,
为什么GR 会是将近100%,SM load/store实际的性能本来就是比cudaMemcpy差很多吗?还是我的使用有问题?谢谢