有一个Linear的算子,我尝试去分析他的Roofline,
该算子的输入尺寸为(96,198,768),权重为(768,3072),输出为(96,198,3072)。
理论分析:
(1)理论上他的计算FLOPs为96 x198 x 768x3972x2 ( mul+add operation)=89690996736FLOPs
(2)如果考虑权重复用,其理论内存访问为96x198x 768x2(2Byte)+ 96x 198x3072x 2(2Byte)+768x3072x 2(2Byte)= 150700032Byte
(3)理论操作密度为595
实际分析:
但我使用ncu分析该kernel时发现,实际操作密度只有0.57
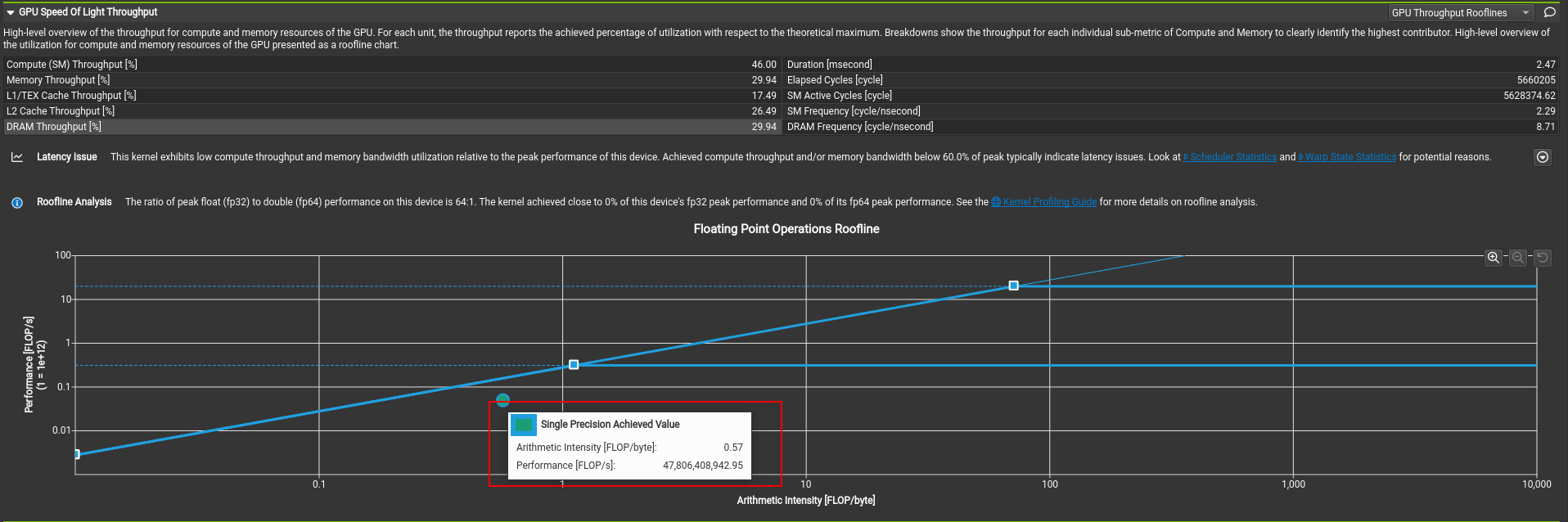
我尝试统计了这些值:
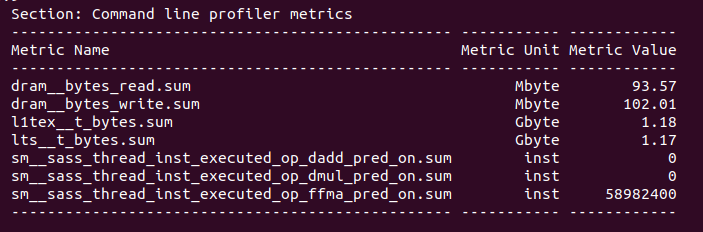
想请问如何解释只需要58982400条FFMA指令就可以完成该kernel的计算呢? 并且为什么操作密度是0.57,统计的规则是什么呢?