推荐系统在在线平台中无处不在,帮助用户浏览数量呈指数级增长的商品和服务。这些模型是推动用户参与的关键。随着行业数据集规模的快速增长,深度学习(DL)推荐模型已经开始利用大量的训练数据来获得传统方法的优势。
目前培养大规模推荐者面临的挑战包括:
[list]
[]庞大的数据集:商业推荐人员接受的培训对象是巨大的数据集,通常是几兆字节的规模。
[]复杂数据预处理与特征工程管线:需要对数据集进行预处理并转换为与DL模型和框架一起使用的形式。此外,特性工程从现有特性中创建了一组广泛的新特性,需要多次迭代才能获得最佳解决方案。
[]输入瓶颈: 数据加载,如果没有得到很好的优化,可能是训练过程中最慢的部分,从而导致对 GPU 等高通量计算设备的利用率不足。
[]大量重复实验:整个数据工程、培训和评估过程通常重复多次,需要大量的时间和计算资源。
[/list]
准备数据集所花费的时间通常超过了训练深度推荐模型本身所需的时间。作为一个具体的例子,使用Facebook提供的 NumPy CPU 脚本 处理太字节数据集需要五天半的时间,而在处理后的数据集上培训DLRM公司(深度学习推荐模型)需要两天的时间,在单个v100 GPU 上则需要不到一个小时。
加速这一数据准备过程对于解决下一代推荐系统所需的数量和规模至关重要。
这篇文章是为具有中高级数据预处理、转换和特性工程背景的开发人员准备的。它只需10-20行高级API代码,就可以帮助处理tb级表格数据的extract transform load(ETL)操作。
NVTabular :快速表格数据转换与加载
为了快速方便地操作这些TB级的数据集, NVIDIA 引入了 NVTabular ,一个推荐系统的特征工程和预处理库。它提供了一个高级抽象来简化代码并使用 RAPIDS cuDF 库加速 GPU 上的计算。
使用 NVTabular ,只需10-20行高级API代码,您就可以建立一个数据工程管道,与优化的基于 CPU 的方法相比,可以实现高达10倍的加速,同时不受数据集大小限制,而不管 GPU / CPU 内存容量如何。
NVTabular 专注于数据准备和数据加载阶段。这是一个常见的推荐系统管道。
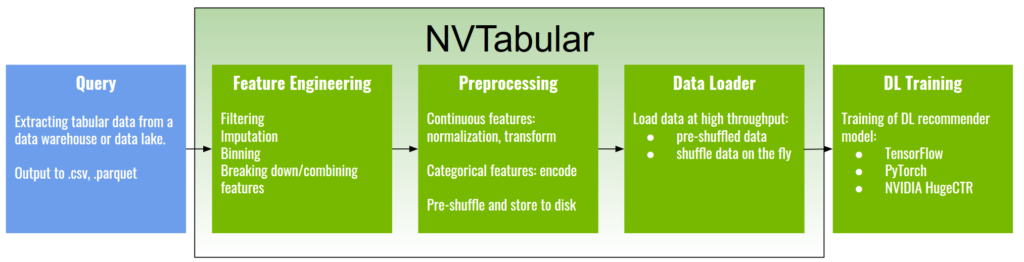
图1。推荐系统培训管道。
获取用于训练推荐模型的数据的第一步是从某个数据源(例如数据仓库或数据湖)进行查询。这个步骤的输出通常是压缩拼花、ORC或CSV格式的表格数据。这类数据集的一个例子是Criteo tbyte click logs 数据集,这是已知最大的公共推荐系统数据集之一。
接下来是特征工程和预处理步骤,例如:
[list]
[]过滤异常值或丢失的值,或创建新的功能来指示某个值丢失
[]缺失数据的填补
[]连续特征的离散化或离散化
[]通过拆分或组合现有功能来创建功能,例如,将日期列分解为周、月、月功能
[]将数值特征标准化为零均值和单位方差,或应用转换,例如使用对数变换
[]使用一个热向量对离散特征进行编码或将其转换为连续整数索引
[/list]
处理后的数据可以被洗牌并以压缩格式保存到磁盘上。可以使用 NVTabular 加速数据加载程序将其加载到DL框架之一,如 TensorFlow 、 PyTorch 或 NVIDIA 推荐者专用培训框架 NVIDIA HugeCTR 。
NVTabular 快速特性工程和转换功能允许为快速实验创建许多数据集变体,而数据加载器使数据以更高的吞吐量提供给DL框架,消除了训练时的输入瓶颈。
在引擎盖下, NVTabular 是建立在 NVIDIA RAPIDS 之上的抽象, GPU 是一个用于数据科学的加速库。 RAPIDS 自带了处理 GPU 数据帧的库,称为 cuDF 。然而,与另一个处理数据帧的流行库 cuDF 和 pandas 相比, NVTabular 有一些突出的优势,总结如下表所示。 Spark 不仅能够处理数据帧,但通常用于预处理大规模的表格数据,因此也包括在比较中。
[table]
[tr][td]特征[/td][td]NVTabular[/td][td]cuDF[/td][td]pandas[/td][td]Spark 3[/td][/tr]
[tr][td]GPU 加速度~[/td][td]10倍[/td][td]10倍[/td][td]不[/td][td]3倍[/td][/tr]
[tr][td]数据集大小限制[/td][td]无限的[/td][td]GPU 存储器[/td][td]CPU 存储器[/td][td]无限的[/td][/tr]
[tr][td]代码复杂度[/td][td]简单[/td][td]适度[/td][td]适度[/td][td]复杂[/td][/tr]
[tr][td]灵活性[/td][td]Mid(但可扩展)[/td][td]高[/td][td]高[/td][td]高[/td][/tr]
[tr][td]代码行~[/td][td]10-20[/td][td]100-1000[/td][td]100-1000[/td][td]300-1000[/td][/tr]
[tr][td]相对I/O成本[/td][td]1[/td][td]#操作数[/td][td]#操作数[/td][td]1+[/td][/tr]
[tr][td]数据加载转换[/td][td]是的[/td][td]不[/td][td]不[/td][td]不[/td][/tr]
[tr][td]推理变换[/td][td]是的[/td][td]不[/td][td]不[/td][td]不[/td][/tr]
[/table]表1。比较数据帧库。
执行ETL所花费的总时间是运行代码的时间和编写代码所用时间的混合。 RAPIDS 团队已经在 GPU 上加速Python数据科学生态系统,通过 cuDF 提供 pandas 操作的加速,通过Apache Spark 3.0的 Spark 到 GPU 的功能,以及通过Dask- cuDF 来加速Dask- pandas 操作。
NVTabular 使用了这些加速,但提供了一个更高级别的API,它集中在推荐系统上,这大大简化了代码复杂性,同时仍然提供了相同级别的性能。图2显示了 NVTabular 相对于其他数据帧库的定位。
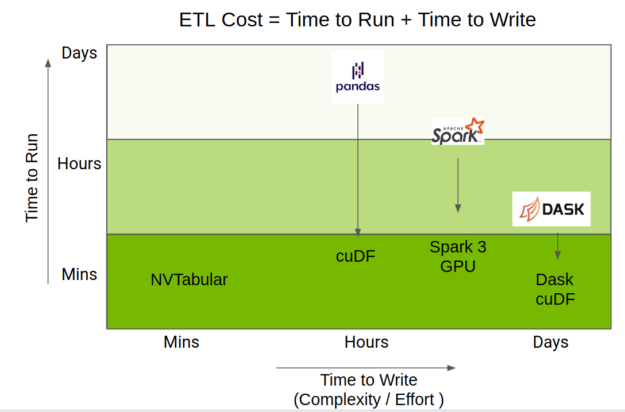
图2。 NVTabular 定位与其他流行的数据帧库。
NVTabular :技术优势
NVTabular 有三大优势:
[list]
[]性能:延迟执行和 GPU 加速将性能提高10倍。
[]规模:数据集操作可扩展到 GPU / CPU 内存之外。
[*]可用性:完成相同的处理管道所需的API调用更少。
[/list]
性能
NVTabular 被设计成最小化通过数据的次数。这是通过延迟执行策略实现的。数据操作直到显式应用阶段才会执行。在第一阶段,这些操作只注册到工作流中。这使得 NVTabular 能够优化需要在整个数据集上迭代的统计信息集合。
一些需要全局统计的运算符示例包括:
[list]
[]规范化数值特征:这依赖于两个统计数据,即整个数据的平均值和标准差。
[]用频率阈值编码类别特征:这需要从整个数据中收集类别发生的统计信息。
[/list]
在处理TB级的数据集时,必须事先仔细规划统计数据收集阶段和转换阶段,避免不必要的数据传递。
NVTabular 最多需要N通过数据,其中N是链式操作的次数。这通常较少,因为延迟执行允许仔细规划和优化工作流。其他库,如 cuDF 和 pandas ,由于其迫切的执行特性,不允许工作流优化,并且可以迭代整个数据集,迭代次数与操作数相同。
NVTabular 不仅为数据预处理提供了一种快速的方法,而且为数据加载到DL框架中提供了一种快速的方法。在 NVTabular 中, NVIDIA 提供了一个在存储到磁盘之前洗牌数据集的选项。统一洗牌的数据集使数据加载器能够读取已在整个数据集中随机分配的连续数据块。
NVTabular 提供了一个选项来控制组合成一个批的块的数量,允许最终用户在性能和真正的随机化之间进行权衡时具有灵活性。当处理超过 CPU 内存的数据集时,这种机制非常关键,并且在训练期间需要每个历元的洗牌。这样一个数据集的完全洗牌可能会比历元的训练时间多出几个数量级。
比例尺
虽然 NVTabular 是在 RAPIDS cuDF 库上构建的,但它在很大程度上改进了 cuDF :数据不仅限于 GPU 甚至 CPU 的内存容量。当数据集适合 GPU 内存时,CuDF可以实现惊人的加速。但是,它并不是为处理扩展到 GPU 内存之外的数据集而设计的。 NVTabular 处理适合 GPU 内存的数据块,支持大于 CPU / GPU 内存的数据集。
可用性
使用 NVTabular 高级API,只需10-20行代码就可以建立复杂的数据转换和预处理管道。
在本节后面,我们将提供一个关于Criteo tbyte数据集的具体工作示例,该数据集包含约1.3 TB的未压缩单击日志,其中包含超过40亿个跨越24天的样本。每个记录包含40个特征:一个表示单击或不单击的标签、13个数字和26个分类特征。
虽然这种规模的数据集很少向公众开放,但这个数据集提供了对真实企业数据规模的一瞥。然而,真实的数据集可能要大得多,因为企业试图利用尽可能多的历史数据来获得更高的准确性。
此数据集的常见预处理步骤包括:
[list]
[]连续特性:输入缺失值(带0),并可选地创建一个附加特征,指示原始特征中的缺失值,进行对数转换,然后将特征规范化为平均值为零,标准偏差为1。
[]范畴特征:如果类别出现频率超过指定阈值,则将类别要素编码为连续整数值。不常见的类别映射到特殊的“未知”类别。
[/list]
下面的代码示例中详细介绍了实现此预处理管道所需的实际代码,其中使用 NVTabular 的代码只有十几行。相比之下,Facebook的DLRM框架中基于 NumPy 的预处理代码是为同一管道定制的300多行代码。
[list]
[]我们指定连续列和分类列。
[]我们定义了一个 NVTabular 工作流并提供了一组训练和验证文件。
[]我们将预处理操作添加到工作流中。
[]我们通过将处理后的数据保存到磁盘来执行。
[/list]
import nvtabular as nvt
import glob
cont_names = ["I"+str(x) for x in range(1, 14)] # specify continuous feature names
cat_names = ["C"+str(x) for x in range(1, 27)] # specify categorical feature names
label_names = ["label"] # specify target feature
columns = label_names + cat_names + cont_names # all feature names
# initialize workflow
proc = nvt.Worfklow(cat_names=cat_names, cont_names=cont_names, label_name=label_names)
# create datsets from input files
train_files = glob.glob("./dataset/train/*.parquet")
valid_files = glob.glob("./dataset/valid/*.parquet")
train_dataset = nvt.dataset(train_files, gpu_memory_frac=0.1)
valid_dataset = nvt.dataset(valid_files, gpu_memory_frac=0.1)
# add feature engineering and preprocessing ops to workflow
proc.add_cont_feature([nvt.ops.ZeroFill(), nvt.ops.LogOp()])
proc.add_cont_preprocess(nvt.ops.Normalize())
proc.add_cat_preprocess(nvt.ops.Categorify(use_frequency=True, freq_threshold=15))
# compute statistics, transform data, export to disk
proc.apply(train_dataset, shuffle=True, output_path="./processed_data/train", num_out_files=len(train_files))
proc.apply(valid_dataset, shuffle=False, output_path="./processed_data/valid", num_out_files=len(valid_files)
对标结果
图3显示了 NVTabular 相对于原始DLRM预处理脚本的相对性能,以及在单节点集群上运行的 Spark 优化ETL进程。值得注意的是培训占用的时间与ETL所用时间的百分比。在基线情况下,ETL与培训的比率几乎完全符合数据科学家花费75%的时间处理数据的俗语。有了 NVTabular ,这种关系就颠倒了。

图3。 NVTabular Criteo比较. GPU ( Tesla V100 32 GB)与 CPU (AWS r5d.24xl,96色,768 GB内存)
使用原始脚本处理数据集和在 CPU 上训练模型所花费的总时间超过一周。经过大量的努力,使用 Spark 进行ETL和 GPU 上的培训可以将时间缩短到4个小时。
使用 NVTabular 和 NVIDIA HugeCTR ,可以将单个 GPU 的迭代时间加快到40分钟,而在使用8X V100 32 GB GPU 的DGX-1服务器上,可以将迭代时间加快到18分钟。在后者的情况下,只有3亿分钟的交互数据被处理。
行动号召
NVTabular 是在 NVIDIA / NVTabular GitHub repo中作为开源工具包提供的。我们在 NVIDIA NGC上提供了Docker图像,在流行的公共数据集上提供了示例脚本和Jupyter笔记本,例如criteotbyte,它允许您在几分钟内启动并运行 NVTabular 。
NVTabular 是 NVIDIA NVIDIA Merlin 的一部分, NVTabular 是构建基于深度学习的高性能推荐系统的框架。有关详细信息,请参见 NVIDIA Merlin :深度推荐系统的应用框架。
这只是一个激动人心的旅程的开始。我们诚挚地邀请您试用这些新开发的工具,为您的推荐系统应用程序提供帮助。您的问题和功能请求将有助于指导未来的发展。
关于作者

Vinh Nguyen
关于阮-Vinh-Nguyen是一位深度学习的工程师和数据科学家,发表了50多篇科学文章,引文超过2500篇。在 NVIDIA ,他的工作涉及广泛的深度学习和人工智能应用,包括语音、语言和视觉处理以及推荐系统。看所有的位置由Vinh Nguyen

Even Oldridge
甚至奥尔德里奇 Even Oldridge是 NVIDIA 的高级应用研究科学家,领导开发 NVTabular 的团队。他拥有计算机视觉博士学位,但在过去的五年里,他一直致力于推荐系统领域,专注于基于深度学习的推荐系统。查看所有文章甚至奥尔德里奇

Mengdi Huang
关于黄孟迪 Mengdi Huang是 NVIDIA 的一名深度学习工程师,在基于DL的人工智能研究和应用领域有四年的工作经验,包括可扩展机器学习、推荐系统以及多模式语言、视觉和语音处理。查看黄孟迪的所有帖子
声明: 此文章是由机器翻译所提供,请参考原文以获取更准确内容 - https://developer.nvidia.com/blog/accelerating-etl-for-recsys-on-gpus-with-nvtabular/