请使用下面的模版提问(创建话题后勾选相应的选项):
Jetson 模组
Jetson AGX Orin
Jetson Orin NX
Jetson Orin Nano
Jetson AGX Xavier
Jetson Xavier NX
Jetson TX 系列
Jetson Nano
Jetson 软件
JetPack 5.1.3
JetPack 5.1.4
JetPack 6.0
JetPack 6.1
DeepStream SDK
NVIDIA Isaac
SDK Manager 管理工具版本
2.1.0
其他
问题描述
你好。
我现在有两个模型,一个检测模型,一个超分模型。模型单独推理都没有问题,但是在程序中使用多线程推理后就会出现问题,输出的画面会撕裂和扭曲,我上传示例代码,onecamdemo是两个模型使用线程运行的demo,sr和yolo是两个engine模型的测试demo
文件连接:https://github.com/A-cvprogrammer/code
将他们放在同一个文件夹就可以复现,谢谢
错误码
错误日志
YanHY
2
srgpu.py 和 yolo256.py 两个文件都使用了默认 CUDA 流,导致访问GPU竞争。
可以尝试改为
self.stream = torch.cuda.Stream()
with torch.cuda.stream(self.stream):
//其他 CUDA 操作
另外 one_cam_demo.py 中尝试添加同步锁
from threading import Lock
with lock:
sr_result, _ = sr_engine.get4srimg(img, (800,600))
再调用以上两个操作时,可以用
torch.cuda.synchronize() //同步完成 CUDA后分别执行显示结果
非常感谢您的回复,
1、关于cuda流,我调试了代码,两者的id不同诶为什么还是能产生竞争呢,理论上不是两个类分别示例化了吗,然后我在网上看说在同一个进程实例化模型可能会导致竞争,但是我使用多进程实例化模型,在多进程里推理也还是会出现这样的问题。
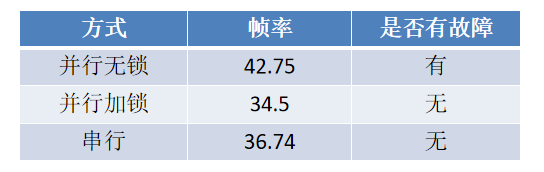
2、我昨天对两个线程使用了lock和串行运行,发现没有问题了,但是推理帧率有显著的下降,因为加lock和torch.cuda.synchronize()相当于串行了,实验表明还没有串行的运行效率高,目前jetson上能实现不加锁的并行吗,因为这个速度对我们挺重要的
期待您的回复
两个不同的stream:
YanHY
4
关键要相关操作在 with torch.cuda.stream(self.stream): 上下文中执行。
或者了解一下 self.stream = torch.cuda.Stream(non_blocking=True)
还有下面的方法。
torch.cuda.set_per_process_memory_fraction(0.5)
torch.cuda.empty_cache()
使用硬件解码器处理视频流
import PyNvCodec as nvc
nvc_decoder = nvc.PyNvDecoder(input_file, gpu_id=0)
谢谢你的回复,通过您的指导这个问题已经被解决了,非常感谢,祝您身体健康,工作顺利。