vLLM + Qwen3-32B-Base on NVIDIA GB10 (CUDA 13 / aarch64)
本文记录在 NVIDIA Spark(GB10) 环境下,使用 CUDA 13 + aarch64 成功运行
vLLM + Qwen3-32B-Base(safetensors) 的完整过程。
目标:可运行、可复现、稳定优先(非性能优先)
STEP 1:创建虚拟环境(Create Virtual Environment)
python3 -m venv ~/venv/vllm-cu130
source ~/venv/vllm-cu130/bin/activate
STEP 2:确认系统与硬件信息(Verify System & GPU)
nvidia-smi
uname -m
期望结果:
- CUDA Version: 13.0
- GPU: NVIDIA GB10
- Architecture: aarch64
说明:
GB10 属于新架构,compute capability = 12.1,是后续问题根源之一。
STEP 3:安装支持 CUDA 13 的 vLLM(实验性)
下载地址(官方 Release):
https://github.com/vllm-project/vllm/releases/download/v0.13.0/vllm-0.13.0+cu130-cp38-abi3-manylinux_2_35_aarch64.whl
pip install -U ~/Desktop/vllm-0.13.0+cu130-cp38-abi3-manylinux_2_35_aarch64.whl
验证 vLLM 是否可导入:
python - <<'PY'
import vllm
print("vllm:", vllm.__version__)
PY
STEP 4:重新安装 PyTorch(关键步骤)
重要说明
vLLM wheel 自带的 PyTorch 并不完全支持 CUDA 13,
如果不手动替换,可能出现:
- torch.cuda.is_available() == False
- Triton / inductor 行为异常
必须手动安装 cu130 分支。
pip uninstall -y torch torchvision torchaudio
pip install torch torchvision torchaudio \
--index-url https://download.pytorch.org/whl/cu130
STEP 5:验证 PyTorch CUDA 是否正常
5.1 CUDA 可用性检查
python - <<'PY'
import torch
print("torch:", torch.__version__)
print("torch cuda:", torch.version.cuda)
print("cuda available:", torch.cuda.is_available())
if torch.cuda.is_available():
print("gpu:", torch.cuda.get_device_name(0))
print("capability:", torch.cuda.get_device_capability(0))
PY
期望:
- torch.cuda.is_available() == True
- capability == (12, 1)
5.2 CUDA MatMul 实际运算验证
python - <<'PY'
import torch, time
a = torch.randn(4096, 4096, device="cuda", dtype=torch.float16)
b = torch.randn(4096, 4096, device="cuda", dtype=torch.float16)
for _ in range(3):
c = a @ b
torch.cuda.synchronize()
t0 = time.time()
c = a @ b
torch.cuda.synchronize()
print("matmul ok, ms:", (time.time()-t0)*1000)
print("mean:", c.float().mean().item())
PY
说明:
这是为了确认 不是“能 import 但不能算” 的假 CUDA。
STEP 6:准备 Qwen3-32B-Base 模型
模型类型:Qwen3-32B-Base(非 instruct)
格式:safetensors
export MODEL_DIR="/home/ziyao/Desktop/AI/Qwen332B"
确认模型结构完整:
test -f "$MODEL_DIR/config.json" && echo "OK: config.json exists" || echo "BAD: path wrong"
验证 transformers 可加载配置:
python - <<'PY'
from transformers import AutoConfig
cfg = AutoConfig.from_pretrained("/home/ziyao/Desktop/AI/Qwen332B", trust_remote_code=True)
print("OK, model_type =", cfg.model_type)
PY
STEP 7:问题出现 —— 默认启动 vLLM 会崩溃
在 不加任何限制 的情况下启动 vLLM,常见错误如下:
Value 'sm_121a' is not defined for option 'gpu-name'
问题根因(Root Cause)
- GB10 compute capability = 12.1
- torch.compile / inductor / Triton 会生成
sm_121a - 当前 ptxas / Triton 不认识 sm_121a
- 属于 CUDA 13 + 新架构未完全适配问题
STEP 8:解决方案 —— 强制 Eager 模式
通过禁用以下组件规避问题:
- torch.compile
- torch inductor
- Triton JIT
- CUDA Graph codegen
使用参数:
--enforce-eager
CUDA_VISIBLE_DEVICES=0 vllm serve /home/ziyao/Desktop/AI/Qwen332B \
--host 0.0.0.0 \
--port 8000 \
--dtype float16 \
--max-model-len 4096 \
--gpu-memory-utilization 0.90 \
--enforce-eager \
--served-model-name qwen3-local
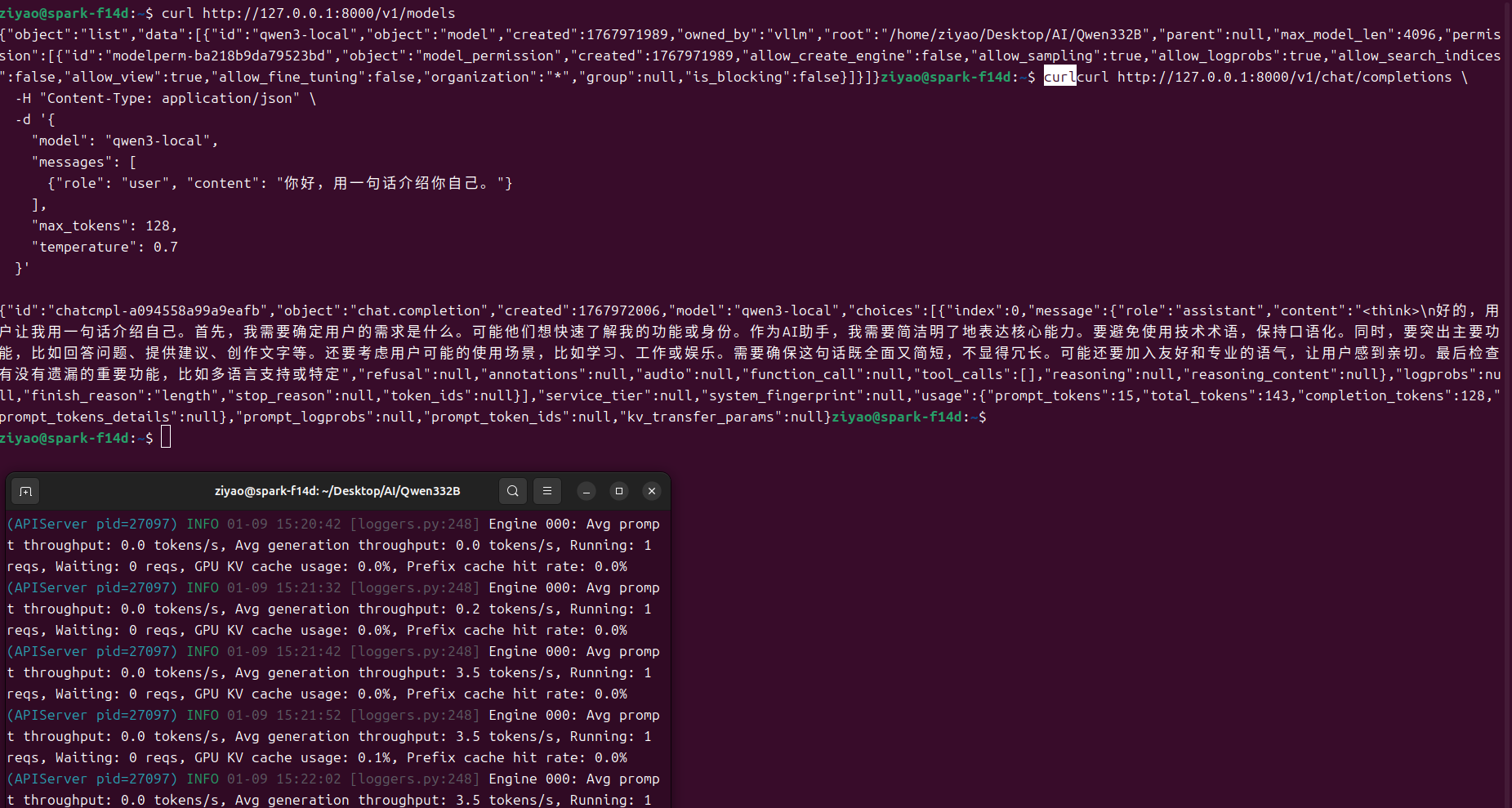
STEP 10:验证 vLLM API 是否正常
curl http://127.0.0.1:8000/v1/models
期望返回中包含:
"qwen3-local"
说明:
说明模型已成功加载并对外提供 OpenAI-compatible API。
总结(Conclusion)
这是我一个新手小白摸索出来的方法,如果大佬们有不用牺牲部分性能加限制参数的方法请务必告诉我,我查这个查了很久终于成功了