- 下面的最小单元测试代码: (不需要关心maxpool2D执行了什么计算,只是Launch kernel 执行计算而已。测试中体现的耗时差异主要在是否申请了
managed memory)
TEST_F(TestAlgorithm, maxPool2d_4) {
const int N = 1, C = 1, H = 5, W = 5;
const int kH = 2, kW = 2, strideH = 1, strideW = 1, padding = 1, dilationH = 2, dilationW = 2;
const int Hout = (H + 2 * padding - dilationH * (kH - 1) - 1) / strideH + 1;
const int Wout = (W + 2 * padding - dilationW * (kW - 1) - 1) / strideW + 1;
const int kSize = N * C * H * W;
const int kSZout = N * C * Hout * Wout;
float *input_cpu;
float *input;
float *output;
int *indices;
input_cpu = (float *)malloc(kSize * sizeof(float));
cudaMalloc(&input, kSize * sizeof(float));
cudaMalloc(&output, kSZout * sizeof(float));
cudaMalloc(&indices, kSZout * sizeof(float));
std::generate(input_cpu, input_cpu + kSize, [i = 0.0]() mutable { return ++i; });
cudaMemcpy(input, input_cpu, kSize * sizeof(float), cudaMemcpyHostToDevice);
std::vector<int> allocCnts{0, 1, 5, 10, 50, 200, 500, 1000};
// std::vector<int> allocCnts{1};
cudaStream_t stream2_;
ASSERT_EQ(cudaSuccess, cudaStreamCreateWithFlags(&stream2_, cudaStreamNonBlocking));
for (int allocCnt : allocCnts) {
printf("alloc cnt: %d\n", allocCnt);
std::vector<void *> ptrs{};
/*********************在这里申请 managed memory,但不会使用************************/
for (int i = 0; i < allocCnt; i++) {
void *ptr = nullptr;
cudaMallocManaged(&ptr, 1024, cudaMemAttachHost);
ptrs.push_back(ptr);
}
for (int j = 0; j < 3; j++) {
auto start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < 1000; i++) {
EXPECT_TRUE(wbe::basicop::maxPool2D(&input[0], &output[0], kSZout, &indices[0], kSZout, N, C, H, W,
kH, kW, strideH, strideW, padding, dilationH, dilationW, stream2_));
EXPECT_EQ(cudaSuccess, cudaStreamSynchronize(stream2_));
}
auto end = std::chrono::high_resolution_clock::now();
printf("high_resolution_clock time: %f ms \n", (end - start).count() / 1000000.0);
}
for (auto ptr : ptrs) {
cudaFree(ptr);
}
}
}
编译后测试耗时结果,很奇怪,这里managed memory并未使用,而且flag是cudaMemAttachHost,随着allocCnt增多,耗时增加越明显,why ?
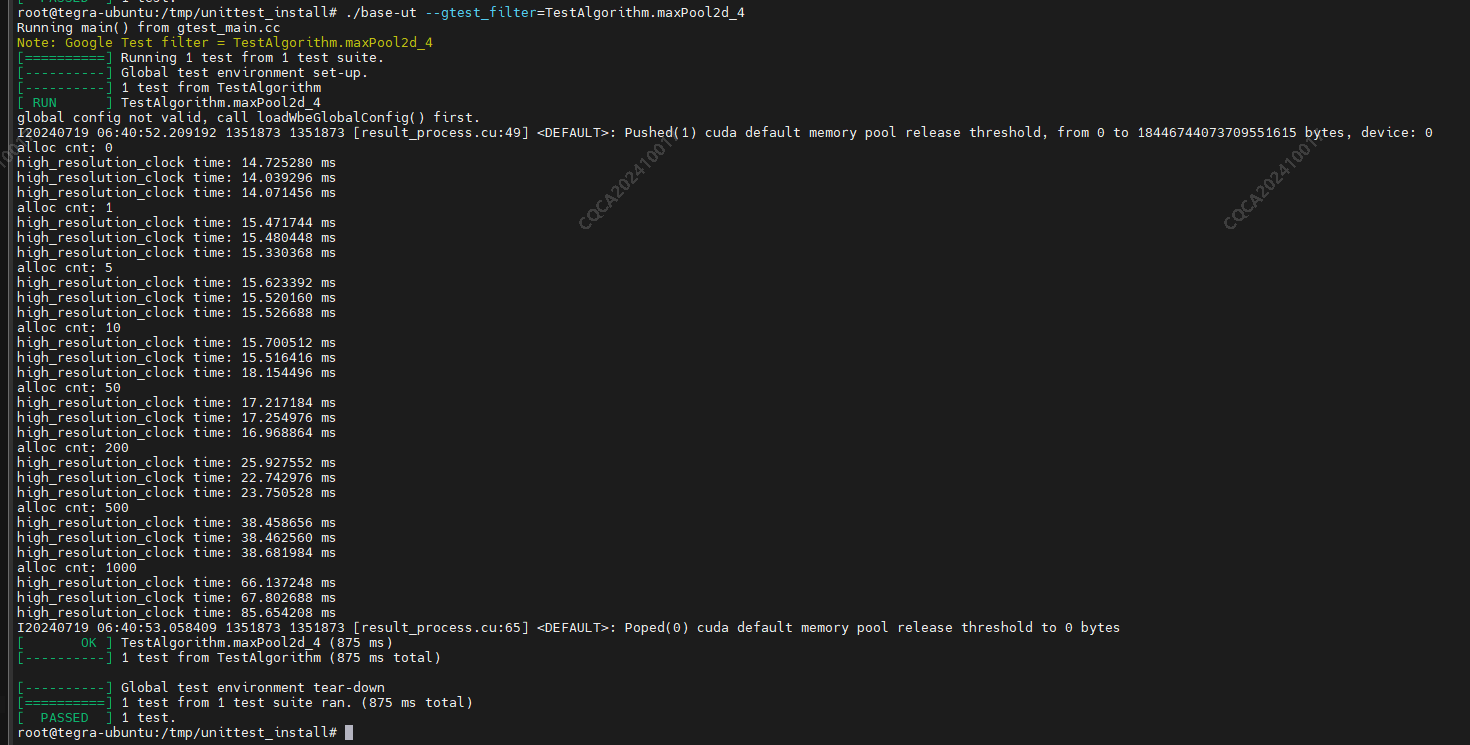
下面改为pinned memory 或者去掉未使用的 managed memory 的代码(其他地方不变),测试耗时每次都一样:
TEST_F(TestAlgorithm, maxPool2d_4) {
const int N = 1, C = 1, H = 5, W = 5;
const int kH = 2, kW = 2, strideH = 1, strideW = 1, padding = 1, dilationH = 2, dilationW = 2;
const int Hout = (H + 2 * padding - dilationH * (kH - 1) - 1) / strideH + 1;
const int Wout = (W + 2 * padding - dilationW * (kW - 1) - 1) / strideW + 1;
const int kSize = N * C * H * W;
const int kSZout = N * C * Hout * Wout;
float *input_cpu;
float *input;
float *output;
int *indices;
input_cpu = (float *)malloc(kSize * sizeof(float));
cudaMalloc(&input, kSize * sizeof(float));
cudaMalloc(&output, kSZout * sizeof(float));
cudaMalloc(&indices, kSZout * sizeof(float));
std::generate(input_cpu, input_cpu + kSize, [i = 0.0]() mutable { return ++i; });
cudaMemcpy(input, input_cpu, kSize * sizeof(float), cudaMemcpyHostToDevice);
std::vector<int> allocCnts{0, 1, 5, 10, 50, 200, 500, 1000};
// std::vector<int> allocCnts{1};
cudaStream_t stream2_;
ASSERT_EQ(cudaSuccess, cudaStreamCreateWithFlags(&stream2_, cudaStreamNonBlocking));
for (int allocCnt : allocCnts) {
printf("alloc cnt: %d\n", allocCnt);
std::vector<void *> ptrs{};
/***********************将这里改为 pinned memory,未使用的内存,能明显降低耗时***************************/
for (int i = 0; i < allocCnt; i++) {
void *ptr = nullptr;
cudaMallocHost(&ptr, 1024);
ptrs.push_back(ptr);
}
for (int j = 0; j < 3; j++) {
auto start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < 1000; i++) {
EXPECT_TRUE(wbe::basicop::maxPool2D(&input[0], &output[0], kSZout, &indices[0], kSZout, N, C, H, W,
kH, kW, strideH, strideW, padding, dilationH, dilationW, stream2_));
EXPECT_EQ(cudaSuccess, cudaStreamSynchronize(stream2_));
}
auto end = std::chrono::high_resolution_clock::now();
printf("high_resolution_clock time: %f ms \n", (end - start).count() / 1000000.0);
}
for (auto ptr : ptrs) {
cudaFreeHost(ptr);
}
}
}
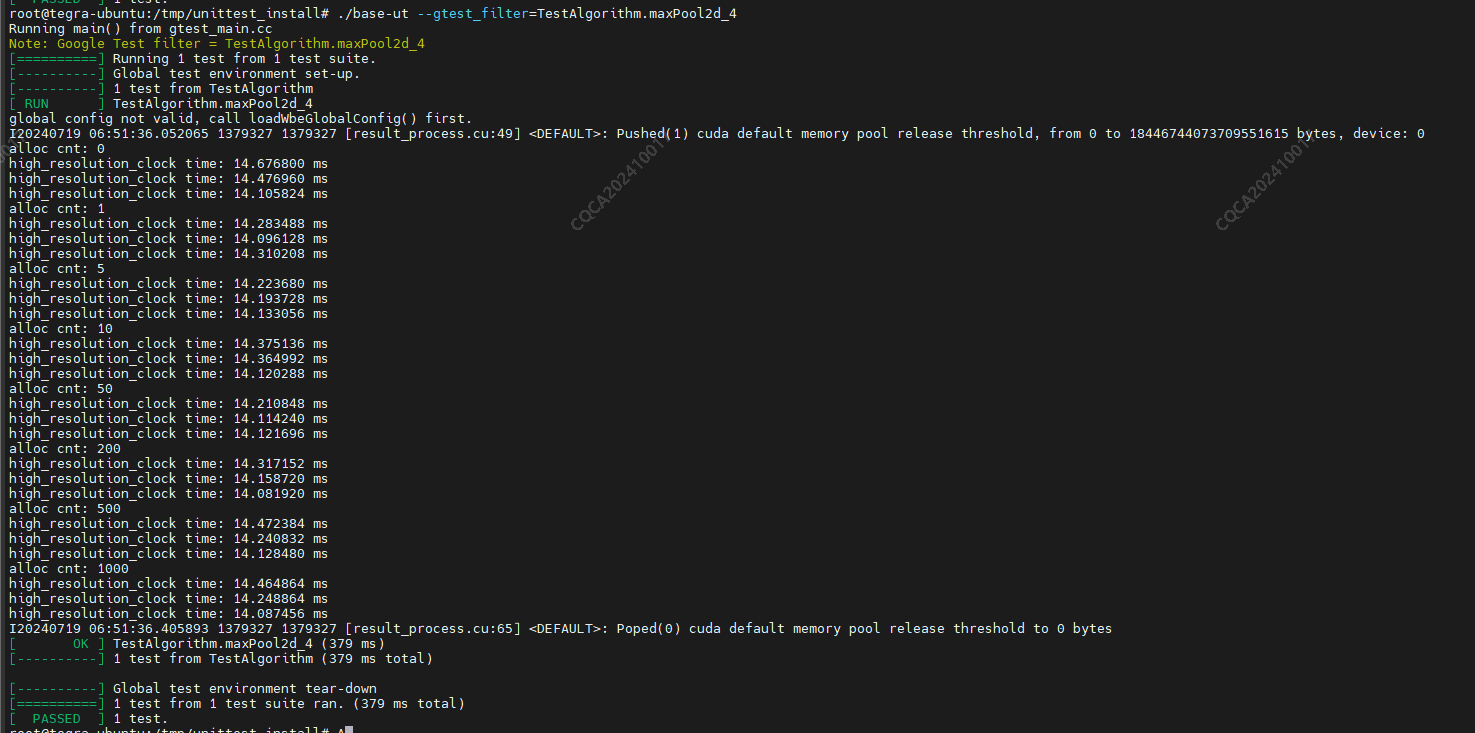
-
疑惑: 谁能帮忙否解答一下
managed meoroy对cudaStreamSync以及Launch kernel 耗时的影响,为什么系统中未使用的managed memory会对 其他kernel 的操作产生负面影响。(我测试了将这些managed meory使用cudaStreamAttachMemAsync绑定到与stream2_不同的流上,结果仍然如此) -
系统环境:
root@tegra-ubuntu:/usr/local/cuda/samples/bin/aarch64/linux/release# cat /etc/nv_version
DRIVE OS: 6.0.6.0
TensorRT: 8.5.10
CUDA: 11.4.20
CUDNN: 8.6.0
DRIVEWORKS: 5.10
root@tegra-ubuntu:/usr/local/cuda/samples/bin/aarch64/linux/release# ./deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Orin"
CUDA Driver Version / Runtime Version 11.8 / 11.4
CUDA Capability Major/Minor version number: 8.7
Total amount of global memory: 10803 MBytes (11327631360 bytes)
(016) Multiprocessors, (128) CUDA Cores/MP: 2048 CUDA Cores
GPU Max Clock rate: 1275 MHz (1.27 GHz)
Memory Clock rate: 1275 Mhz
Memory Bus Width: 128-bit
L2 Cache Size: 4194304 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 167936 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1536
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: Yes
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 0 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.8, CUDA Runtime Version = 11.4, NumDevs = 1