NVIDIA 开发者论坛
使用cooperative_groups::memcpy_async从global拷贝到shared时,我使用了pingpangbuffer,但是带宽还是只有96%左右,能进一步优化到100%么
加速计算
CUDA
how-to
user2176
2025 年6 月 26 日 08:16
1
如题目。
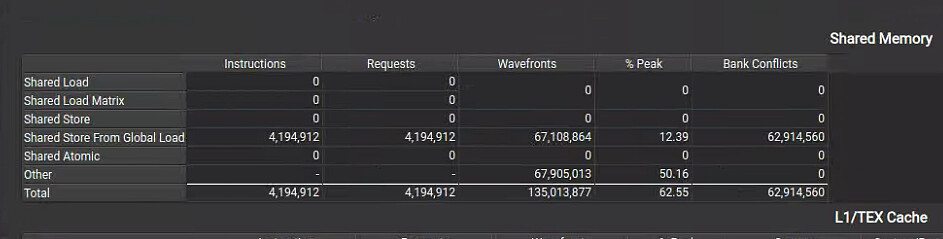
image
943×239 43.3 KB
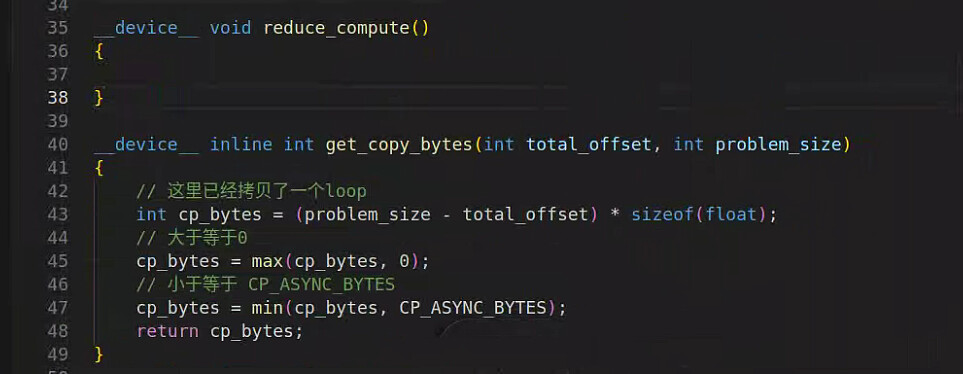
reduce_compute我用的是一个空实现
image
963×374 63.2 KB
image
1647×262 99.2 KB
详细代码参见:
cuda/async_copy/async_copy_test.cu · magic/AIDeploy - Gitee.com